ASN — l'autoroute du scraping
Retour d'expérience sur la construction d'un scraper robuste sans exploser le budget proxy.

ASN — l’autoroute du scraping
Comment j’ai réduit mes coûts de proxy et arrêté de me battre avec les 429
Avertissement : cet article documente une recherche technique et une analyse de marché. Certaines captures peuvent contenir des données sensibles historiques, mais elles ne sont plus exploitables en production. Le choix de ne pas flouter est volontaire, pour partager une méthode réelle et vérifiable. Les retours critiques sont les bienvenus.
En informatique, beaucoup de problèmes deviennent plus simples quand on trouve une bonne analogie dans le monde réel. Pour moi, cette analogie a été l’autoroute = l’ASN.
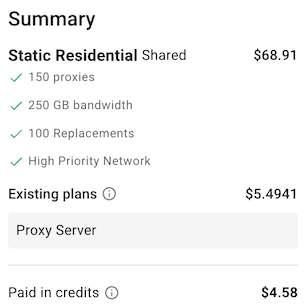 Résultat visible sur la facture proxy après optimisation.
Résultat visible sur la facture proxy après optimisation.
Le chiffre est volontairement marquant, mais le point important est la méthode. Oui, passer directement sur du proxy résidentiel premium (ou un autre service, par exemple Bright Data) peut souvent augmenter le taux de succès plus vite1. Mais ce confort a un coût élevé et masque la cause réelle des erreurs. Ici, je partage surtout une synthèse de trois mois d’ajustements sur plusieurs pools mondiaux pour garder la performance sans dépendre uniquement du budget. Dans la pratique, beaucoup de solutions “scraper-as-a-service” restent coûteuses et peu fiables sur des cibles spécifiques (par exemple Leboncoin ou Steam Market), d’où l’intérêt de construire une chaîne adaptée à son propre cas d’usage.
L’argument décisif a été la détection des réponses “bouchons”. Vous contournez Cloudflare, le serveur répond 200, vous recevez du HTML… mais ce n’est qu’une page vide ou un faux contenu. Pour un service pay as you go, la requête est facturée comme “réussie”, alors que le résultat métier est nul. C’est l’équivalent d’une enveloppe livrée sans lettre à l’intérieur.

Livrer une réponse ne veut pas dire livrer la donnée utile.
Dans cet article, j’explique comment et pourquoi cela a fonctionné.
Sommaire rapide
- Comment tout a commencé
- Ma base de défense
- Une observation étrange
- Hypothèse ASN
- Comment je l’ai vérifié
- Le système “Feu tricolore”
- Le rôle de l’ASN dans le “Feu tricolore”
- Résultat
- Pourquoi l’analogie routière fonctionne
- Conclusion - ASNRank.com
- Ce que vous pouvez faire dès maintenant
Comment tout a commencé
Pour le contexte métier derrière mes tests, j’ai aussi publié un article dédié : Pourquoi Steam Market est un excellent terrain d’apprentissage.
J’ai travaillé presque en continu (un marathon de trois mois, sans jours de repos) sur mon propre scraper. Je ne partais pas totalement de zéro : j’avais déjà des scripts Google Apps Script (.gs) en production. gXd.node/scripts
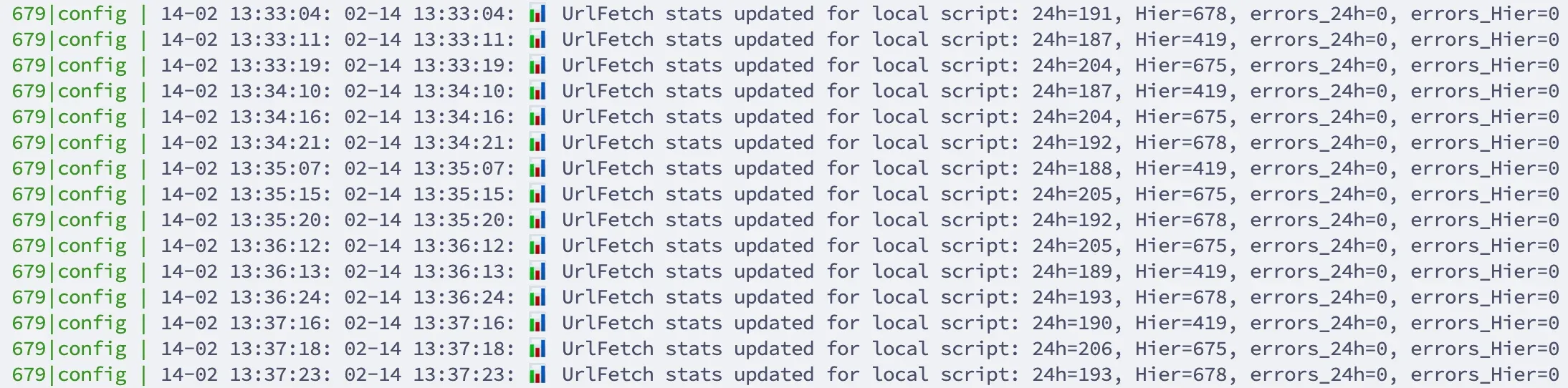 Mais avec le temps, le taux de succès de
Mais avec le temps, le taux de succès de urlFetch pouvait tomber vers 15 % sur certaines cibles, ce qui devenait critique. Même avec une limite quotidienne théorique élevée (souvent citée autour de 20k requêtes/jour2), les limites réelles d’usage restent plus complexes. En pratique, sur mon scénario, j’ai constaté une zone de stabilité autour de 10k requêtes/jour avec urlFetch, mais ce seuil reste dynamique : en augmentant la fréquence, il m’est déjà arrivé de voir des erreurs apparaître avant ce volume.
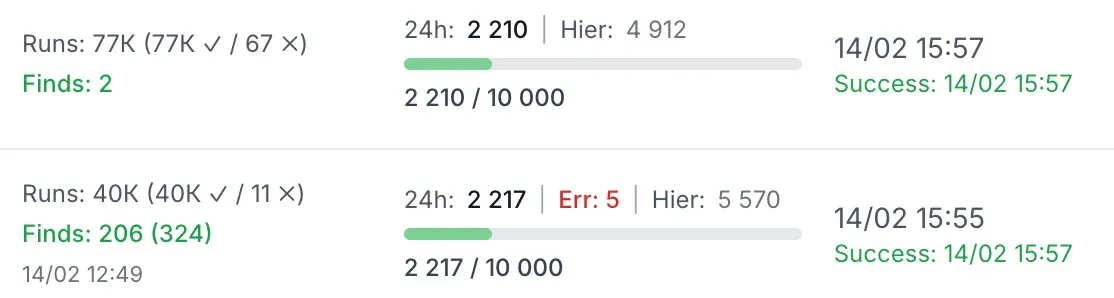
J’ai donc progressivement complexifié l’architecture.
Avant, tout était simple :
- ajouter du jitter,
- limiter la fréquence,
- activer la rotation d’IP,
- changer de pays (dans de rares cas)
Mais ces dernières années (notamment avec l’essor de l’IA), les backends des grands services se sont beaucoup complexifiés. Les méthodes simples ont cessé de fonctionner.
Les erreurs 429 ont commencé à apparaître même avec une charge prudente, y compris en appliquant d’anciennes méthodes de contournement.
Je ne dépassais pourtant jamais 1 requête/seconde et je n’utilisais pas de multi-thread agressif. En moyenne, chaque script restait autour de 1 requête/minute vers le service cible. Le reste du trafic passait sur des canaux prioritaires (API internes, base de données, services système), donc hors du flux de scraping classique.
Ma base de défense (version renforcée anti-blocage)
Au moment des tests, j’avais déjà un système assez élaboré :
- pas plus d’une requête par seconde sur 100+ proxys,
- timing dynamique + jitter à 15 %
1 2 3 4
function withJitter(baseDelayMs = 1000, jitterPercent = 0.15) { const delta = baseDelayMs * jitterPercent; return Math.round(baseDelayMs + (Math.random() * 2 - 1) * delta); }
- changement automatique d’adresses
1 2 3 4 5 6 7 8 9 10 11 12
class ProxyRotator { constructor(proxies) { this.proxies = proxies; this.index = 0; } next() { const proxy = this.proxies[this.index % this.proxies.length]; this.index += 1; return proxy; } }
- chaine de repli : Google → Proxy → Node La logique est volontairement progressive : on tente d’abord les adresses Google (meilleure latence/coût), puis on passe sur les proxys rotatifs, et enfin sur des instances IPv4 dédiées (pool privé utilisé uniquement par moi) quand la cible devient trop restrictive.

- serveurs propres dans plusieurs datacenters avec des IPv4 “propres”
Les nœuds sont aujourd’hui répartis entre la France, l’Allemagne, les Pays-Bas et les États-Unis. L’extension vers Singapour, la Suisse et de nouveaux points aux États-Unis est planifiée, mais ce n’est pas prioritaire pour l’instant.
Le taux de disponibilité actuel se maintient globalement entre 98 % et 99 %, ce qui permet de prioriser l’optimisation logicielle avant l’expansion géographique. 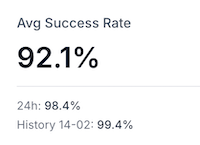
Logs sur le serveur gXd.node gXd.node/logs/scraper-traffic.log
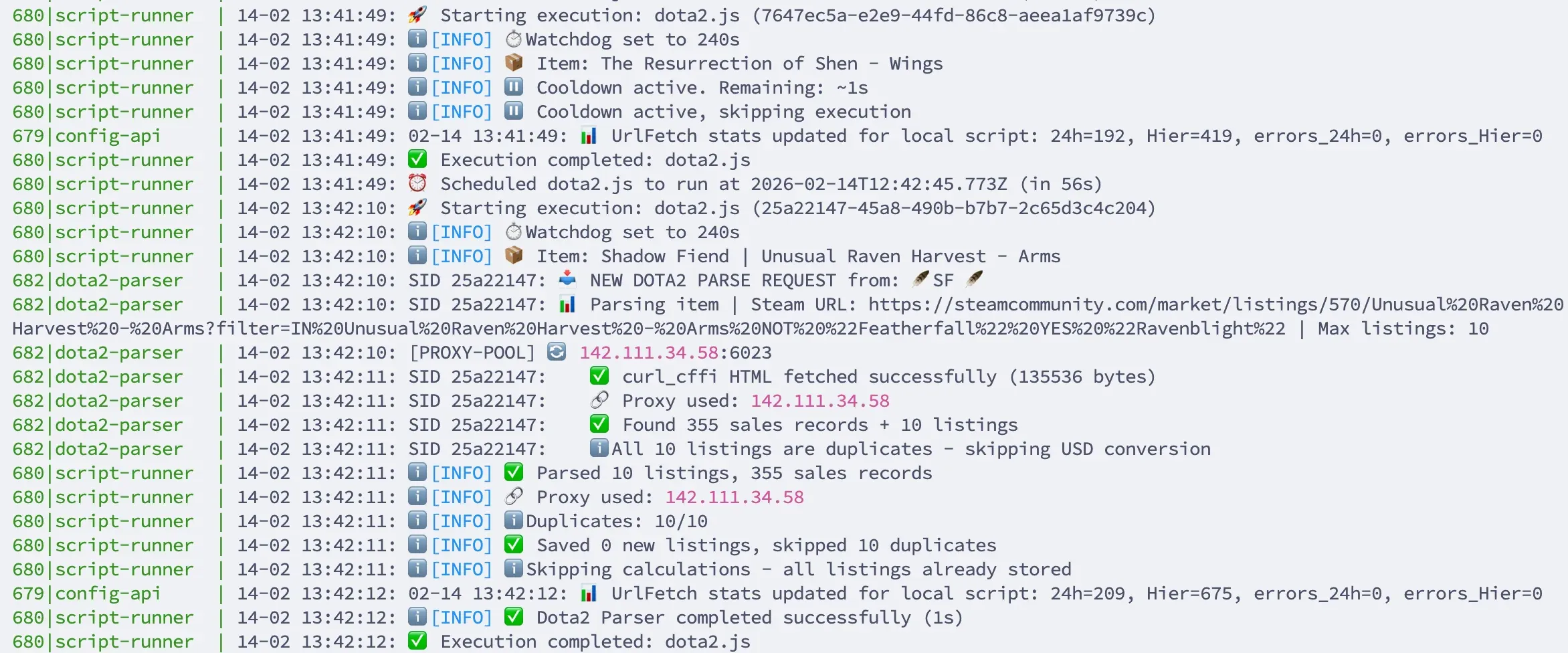
- système de rotation “Feu tricolore”,
- émulation de différents appareils et navigateurs.
Extraits simplifiés de la logique (version pédagogique) :
1
2
3
4
5
6
7
8
9
10
11
async function fetchWithFallback(request) {
try {
return await fetchViaGoogle(request);
} catch {
try {
return await fetchViaProxy(request);
} catch {
return await fetchViaNode(request);
}
}
}
Sur le papier, tout était correct. Mais les résultats variaient toujours fortement selon le pays et selon les pools.
Une observation étrange
Avec le temps, j’ai remarqué une régularité intéressante. Dans un même pays, différents proxys affichaient :
- 90 % de taux de succès,
- 70 %,
- parfois moins de 50 %.
La capture ci-dessous confirme l’idée : à pays égal, le taux de réussite varie fortement selon l’ASN et selon les blocs d’adresses associés.
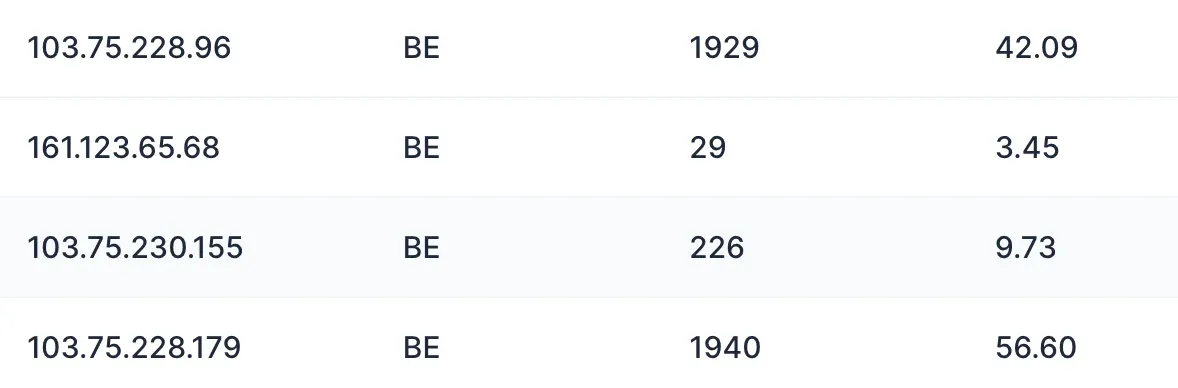
On remarque aussi que l’ASN “faible” a moins de requêtes. Ce n’est pas un biais de mesure : c’est l’effet direct de l’optimisation.
Dès qu’un proxy montre une dérive (429, timeout, latence instable), il est remplacé rapidement. L’objectif n’est pas d’accumuler 1000 échecs sur un proxy mort, mais de couper la perte le plus tôt possible.
Le seuil de remplacement reste volontairement individuel : il dépend du coût du pool, de la tolérance aux erreurs et du rythme de collecte.
Pourtant :
- la charge était identique,
- le comportement identique,
- le timing identique.
La différence se résumait à un seul paramètre : l’ASN.
Les serveurs restent en ligne, mais la qualité du passage peut se dégrader brutalement. Le but est donc de choisir les “autoroutes ASN” les moins saturées pour garder un trafic stable et rentable.

Hypothèse : les limites ne sont pas par IP, mais par ASN
Une hypothèse s’est imposée :
Les services modernes limitent de plus en plus non pas les IP isolées, mais des blocs d’adresses de systèmes autonomes entiers (ASN).
La logique est simple : Si un bloc ASN contient beaucoup d’activité suspecte, il est plus simple de ralentir tout le bloc que de filtrer adresse par adresse.
Conséquences :
- même des IP “propres” commencent à recevoir des 429,
- le taux de succès baisse,
- les coûts augmentent.
Si, dans le même bloc ASN (/24 /23 /22 etc.), quelqu’un d’autre fait du scraping agressif, vous en subissez les effets.
Comment je l’ai vérifié
J’ai commencé à collecter des statistiques par ASN :
- taux de succès,
- nombre de 429,
- temps de dégradation,
- récupération.
Après quelques semaines, une tendance claire est apparue :
- dès qu’un ASN “décroche”,
- toutes les IP en son sein chutent,
- changer d’adresse n’aide pas (changer d’ASN - oui).
Ce n’est pas une preuve formelle, mais la corrélation était trop stable pour être un hasard.
Un point important : certaines baisses de performance viennent d’incidents globaux hors de contrôle local. Lors de perturbations Cloudflare à grande échelle, plusieurs pools peuvent chuter en parallèle, même avec une bonne hygiène de scraping.

À l’échelle d’Internet, les incidents des grands opérateurs deviennent vite des problèmes partagés.
Le système “Feu tricolore”
Pour automatiser la qualité des proxys, j’ai mis en place un système “Feu tricolore”. Le principe est simple, comme en logistique.
| État | Condition | Action |
|---|---|---|
| Vert | Adresse stable, succès au-dessus du seuil | Utilisation active dans la rotation |
| Jaune | Série de 10 erreurs consécutives | Mise en pause pendant quelques heures |
| Rouge | Nouvelle dérive après phase de repos | Exclusion du pool |
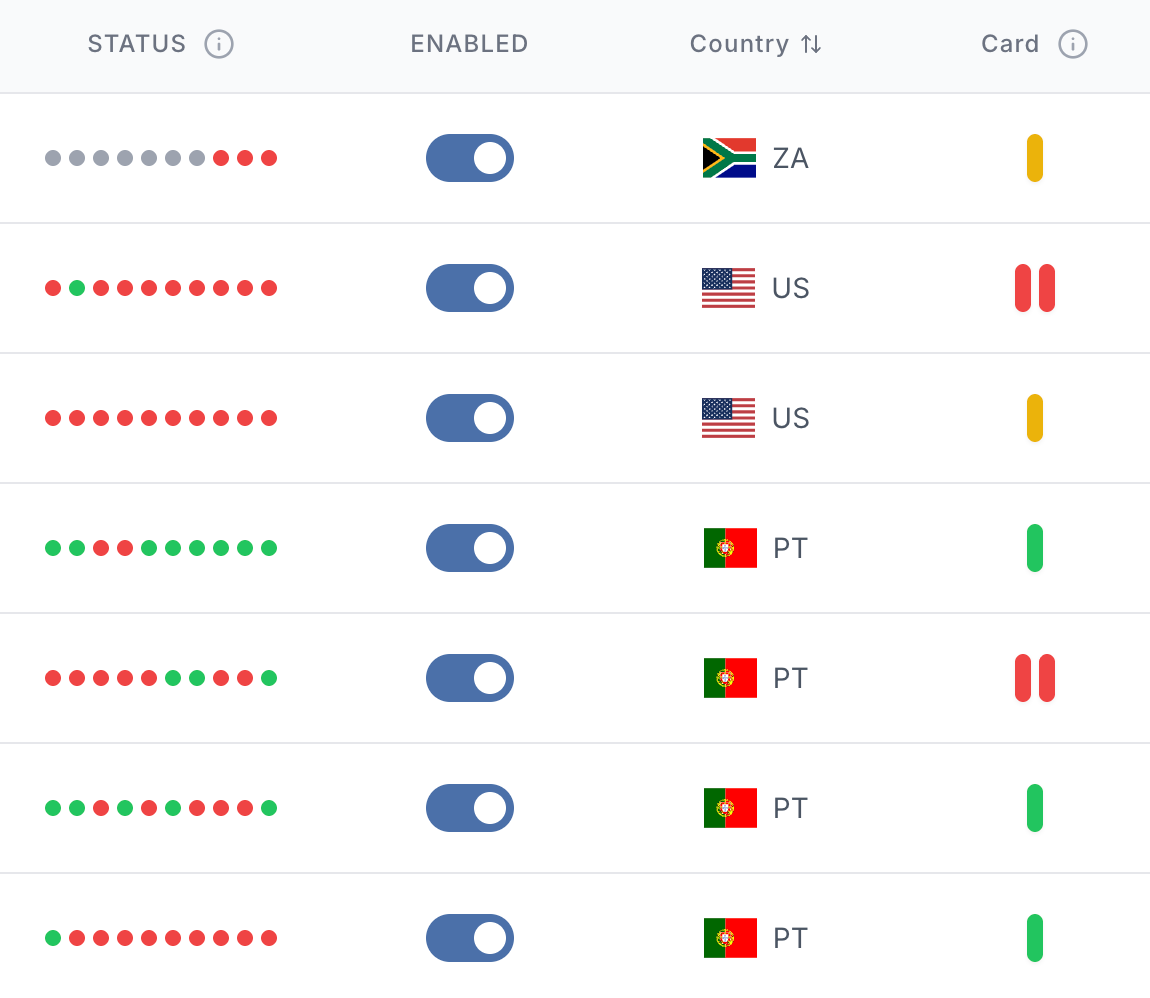
Ce workflow illustre la vérification continue de la “route” (l’ASN) et pas seulement d’une IP isolée.
Le rôle de l’ASN dans le “Feu tricolore”
Avec le temps, j’ai ajouté un niveau d’agrégation :
Adresse → ASN → Pool.
Si plusieurs IP d’un même ASN commencent à générer des erreurs, la priorité de toute la plage baisse.
En pratique, le système apprend à éviter les autoroutes problématiques.
En parallèle, un job serveur vérifie plusieurs fois par jour les nouveaux masques réseau et les compare à l’historique interne. Cette brique n’est pas fournie nativement par Webshare: c’est une couche maison qui améliore la sélection proactive des pools.

Sans endpoint exploitable, même un très bon assistant IA ne peut pas deviner le flux réel. Il faut d’abord comprendre comment la page génère son hypertexte dynamique pour automatiser proprement.
Pourquoi c’est utile
Imaginons :
- un proxy a 99 % de réussite,
- puis il se dégrade,
- à cause de la rotation, le système ne le remarque que plusieurs jours après.
Pendant ce temps, des milliers de requêtes partent dans le vide, avec un coût réel.
Le “Feu tricolore” permet de filtrer les mauvaises adresses en quelques heures, pas en semaines.
Résultat
Après l’intégration de l’analyse ASN et du “Feu tricolore” :
- les 429 ont diminué plusieurs fois,
- le taux de succès a augmenté,
- les proxys sont utilisés plus efficacement,
- une partie des pools a été entièrement remplacée.
Résultat financier :
| Période | Dépenses |
|---|---|
| Avant | 68 $ |
| Après | 5,50 $ |
Pour la même charge.
Pourquoi l’analogie routière fonctionne
Un ASN, c’est une autoroute.
- Les IP sont les voitures.
- Les proxys sont les conducteurs.
- Le trafic est la marchandise.
On peut changer de voitures, mais si la route est saturée, on reste bloqué. J’ai arrêté de me battre avec les voitures individuelles et j’ai commencé à choisir les routes.
Conclusion - ASNRank.com
Après ce travail, j’ai lancé ASNRank.com pour industrialiser cette logique de scoring réseau. Le service centralise le classement des ASN, le suivi de dérive et la priorisation des routes selon la qualité réelle.
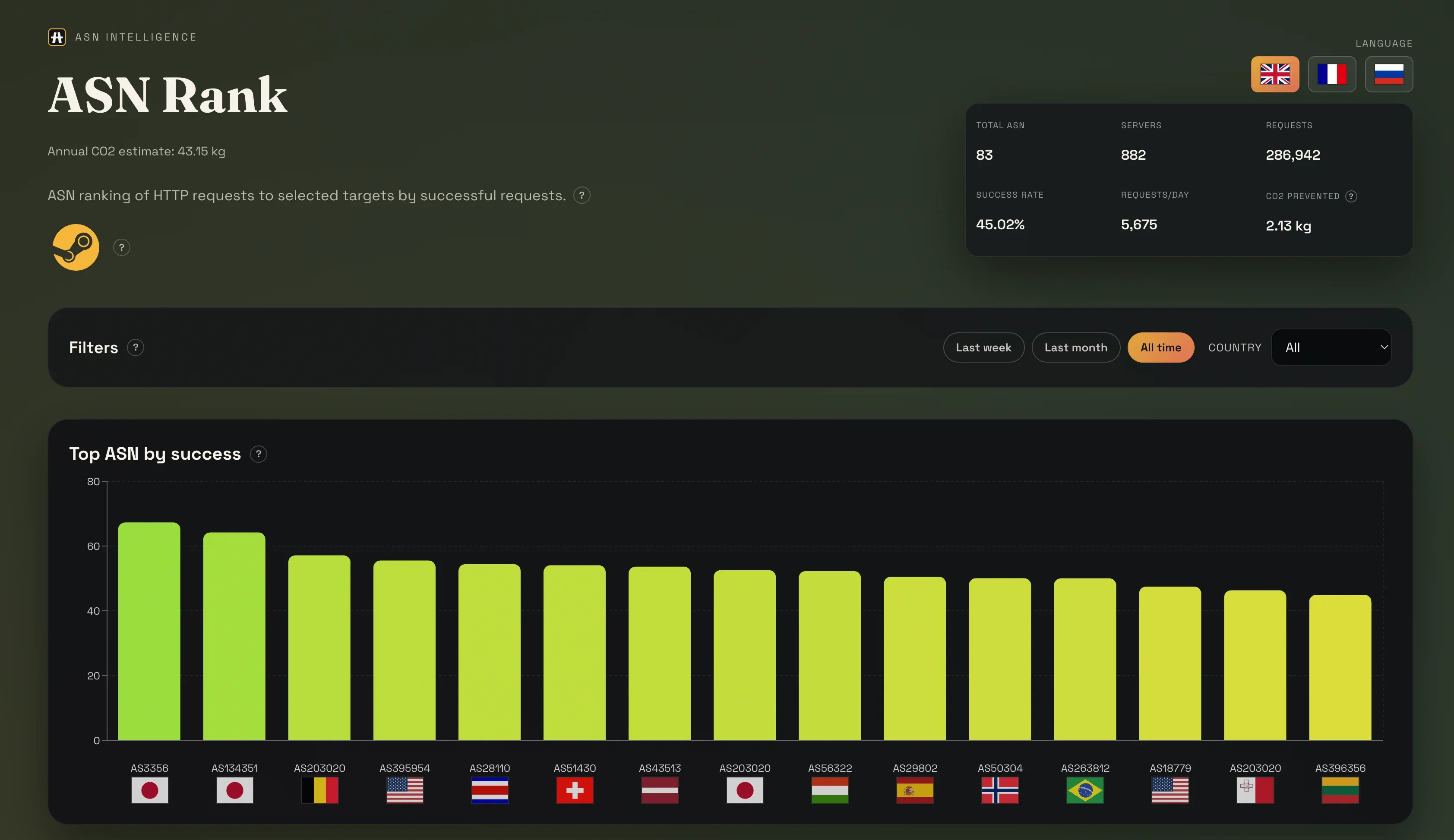
Un article dédié est en préparation :
- ASNRank.com — brouillon de l’article en cours de rédaction (publication à venir).
Le point central est simple : En 2025, lutter contre les blocages seulement au niveau IP n’a plus de sens.
Il faut travailler :
- avec les ASN,
- avec la réputation des réseaux,
- avec la dégradation dynamique,
- avec un contrôle qualité automatique.
Sinon, on brûle simplement son budget.
Ce que vous pouvez faire dès maintenant
Si vous faites du scraping :
- Commencez à loguer les ASN.
- Comparez le taux de succès par plages.
- Désactivez les réseaux problématiques en bloc.
- Automatisez la sélection.
- Ne faites pas confiance aux pools “bon marché” sans statistiques.
Cela se rentabilise très vite.
Merci pour votre attention !
Les proxys résidentiels premium améliorent souvent la délivrabilité, mais leur coût mensuel peut vite dépasser celui d’une optimisation technique sur ASN. ↩︎
La limite “20k/jour” est une référence fréquente selon les configurations, mais la limite utile dépend aussi du type de script, de la cible et des quotas réellement appliqués. ↩︎